Apps do work; work takes time. Spend too much time doing work, and users get frustrated.
Naturally, you can try to speed up the work somehow - make your code do less work, optimize slow code paths, put your servers closer to databases. But alas, for some situations even the fastest programs are still too slow.
Fortunately, much of the work to do is work that’s already been done before. Can’t we just… reuse that work?

It’s not cheating, it’s just looking at work that’s already been done.
In the context of web apps, that work could be CPU-bound, like performing a costly calculation, or IO-bound, like downloading files from the server or fetching data from a database By storing the result of that work, you can skip the work the next time you need it.
The basic principle is simple: Every possible bit of data is identified with some key, like user-1 or /favicon.ico or fibonacci-25. Before getting the data from its source, we check the cache to see if it’s already there. If it is, great! We return the data. If not, we do the expensive operation, put the result in the cache, and return that to the user.
Sounds simple, right? What could possibly go wrong?
Cache Keys
For starters, you’ve got to be careful about making sure you put enough information into your keys. Take this filter menu for example.
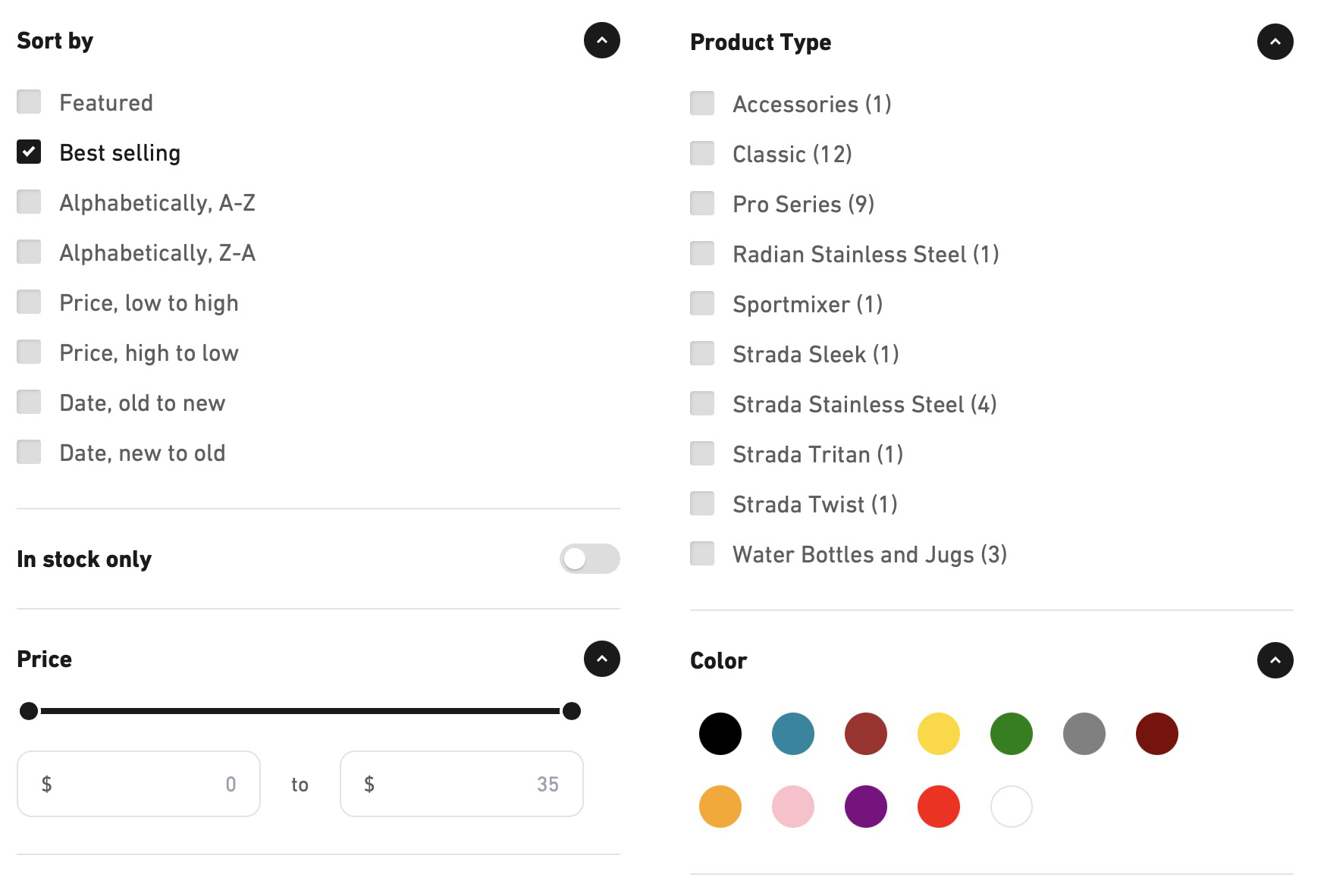
Suppose we wanted to cache the results for a user. Here, we’ve got five categories of things. Type and Color can be multiple values at the same time, while Price can be a granular scale of values. How do you come up with a cache key for this data?
It’s important to remember that cache keys need to exactly represent the data they store. Suppose we forget to include the color input in our cache key. Maybe the cache key is something like ${sort}-${inStock}-${priceLow}-${priceHigh}-${types.join(',')}.
Our first user comes, filters by red products, and the results get put in the cache with the key selling-false-0-35-, which is the default key.
Then the next user comes along and filters by yellow. The cache key is selling-false-0-35-.
See the problem?
Because we’re missing color in our cache key, user 2 will get the same results as user 1, even though they requested a totally different set of colors.
This also illustrates how as your cached function has more inputs, the cache key becomes more complicated. Eventually your cache key becomes so granular that it might not even be worth it to cache the data at all.
It wouldn’t be a problem if we had unlimited storage, but alas - you will eventually run out of space and something will have to be removed from the cache.
But there’s another, likely more important, reason for removing things from the cache - eventually the underlying data will change. Unless the cache is updated with it, now your cache is returning outdated data.
Cache Invalidation & Eviction
There are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.
In an ideal world, any time the underlying data changes, you could determine exactly what cache keys use that data and just delete those items. This provides the most granular, exact caching that is always up-to-date, but it can take effort to do well.
Alternatively, the cache itself can make sure the data is fresh. Perhaps it includes a modified date that it can use to quickly query the source database to know if the data has changed.
A safer fallback - one that risks returning outdated data, but can still work most of the time - is to set some kind of cache expiration or eviction policy. For example:
- items only remain in the cache for n seconds
- items are removed from the cache at a specific time
- the cache only contains n number of items, removing the oldest item (LRU, or least-recently used), infrequently accessed items (LFU, or least-frequently used), or a random item when a new item is added
- treating items as stale after a certain time and returning the old cached entry while new data is fetched - also knows as “stale while revalidate”
Which combination of strategies you use depends on what the data is and where it is cached. For example, a static website might use the Cache-Control header to have the browser cache the site for a certain amount of time, while a dynamic filter like we saw above might only keep a certain number of cached filters using a server-side LRU cache.
Cache Storage
For web apps, there’s a whole spectrum of places where you might want to cache:
- Server Cache: server-side, sometimes private, cached data that persists between requests. Might be shared between servers using an external data store like Redis.
- Request Cache: cached data that persists for the duration of a request to avoid multiple fetches to the same resource and solving the n+1 problem in GraphQL servers. Dataloader and React.cache are both examples of request caches.
- CDN Cache, or Shared Cache: cached data that is replicated in datacenters across the world. The data might come from multiple servers and be consumed by multiple clients. Shared caches can be instructed to cache HTTP responses using the
Cache-Control: s-maxagedirective. - HTTP Cache: the browser version of Shared Caches. Also controlled using the
Cache-Controlheader. There’s no real way to invalidate the HTTP Cache without the user specifically clearing it, so it’s good to be cautious with long expires times. It works especially well for static assets that don’t change frequently, like images, CSS files, or JavaScript. Often these assets have content hashes in their filenames, which treats them as new cache entries when the filename changes. - Browser Cache: persistent storage within browsers that can be accessed through JavaScript and Service Workers. This includes the Caches API, which service workers can use to replace responses to requests to support offline access, IndexedDB for persistent storage, or in-memory caches like TanStack Query that are cleared when the page is closed or refreshed.
Each of these has different uses, capabilities and limitations. They can be used individually, or together within the same app to speed it up. Naturally you don’t have to use all of them at the same time.
As a rule of thumb, start with HTTP caching followed by Server Caching. Those two will provide the biggest speed improvements with relatively low effort.
Hopefully this helps clear up some of the basics of caching. In the future we hope to have a whole series of blog posts going into the intricacies of each of these caching strategies. Until then, may your data be fresh and your caches invalidate when you want them to.